近日,我院鲁剑锋教授以武汉科技大学为第一单位,以第一作者/通讯作者在中国计算机学会(CCF)推荐的A类期刊IEEE Journal on Selected Areas in Communications和B类期刊ACM Transactions on Internet Technology,以及中国自动化学会(CAA)推荐的A类期刊IEEE Transactions on Industrial Informatics和IEEE Transactions on Computational Social Systems连续发表和录用了六篇高水平期刊论文,有力推进了物联网和人工智能交叉领域的前沿性研究工作,扩大了武汉科技大学计算机科学与技术学科在该领域的学术影响力。
论文1:Blockchain-Enabled Task Offloading with Energy Harvesting in Multi-UAV -assisted IoT Networks: A Multi-agent DRL Approach (IEEE Journal on Selected Areas in Communications)
无人机作为空中基站辅助物联网是一项极具前景的技术,可解决诸如扩展网络覆盖、增强网络性能、向物联网设备传输能量、以及在物联网设备上执行计算密集型任务等问题。由于异构的物联网设备有限的处理能力,从而无法长时间执行资源密集型活动。此外,物联网易受安全威胁和自然灾害的影响,限制了其实时应用的执行。尽管已经有许多尝试通过能量收集的计算卸载来解决资源短缺问题,截至目前,对紧急情况和脆弱性问题的研究仍然不足。因此,本文提出了一个基于区块链和多智能体深度强化学习的集成框架,用于在多无人机辅助物联网中使用能量收集进行计算卸载,其中物联网设备从无人机获取计算和能量源。首先,将优化问题表述为计算卸载和能量收集问题的联合优化问题,同时考虑到最优资源价格。其次,将优化问题建模为Stackelberg博弈,通过允许物联网设备和无人机不断调整其资源需求和定价策略来研究它们之间的交互。特别地。所定义的形式化问题可以通过随机博弈模型间接解决,可最小化物联网设备的计算成本,同时最大化无人机的效用。相应的,设计了一个基于多智能体深度强化学习的算法,采用了集中训练和分散执行策略,利用算法自身动态性和高维特性,解决了所定义的问题,并通过广泛的实验结果进一步证明了所提出的框架的优越性。
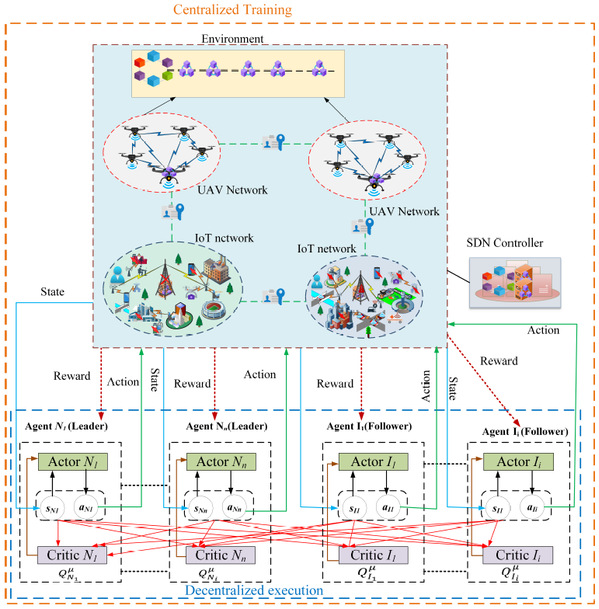
图 SEQ 图 \* ARABIC 1. 基于区块链的多UAV辅助物联网中的MADDPG框架
论文2:Towards Personalized Federated Learning via Group Collaboration in IIoT (IEEE Transactions on Industrial Informatics)
尽管联邦学习已经在多个领域得到了快速发展,但是当与工业物联网技术相结合时,依然面临数据、模型以及边缘设备的异构性挑战。现有的研究工作主要关注于如何通过采用全局协作、聚类协作或成对协作模式实现的个性化模型的训练。然而,全局协作模式无法解决在非独立同分布数据的应用场景,聚类协作模式由于单一的聚类模式和高计算成本使得应用受限,成对协作模式的协作范围较小并且通信成本高昂。针对以上问题,本文从多方博弈视角,提出了一种新颖的组协同个性化联邦框架以解决现有协同模式存在的共性问题。首先,在个性化联邦中将组协同模式建模成一个多领导者多追随者的Stackelberg博弈,利用博弈收益的势函数特征,设计了ε-贪婪反应策略来计算其唯一的均衡解。考虑到博弈均衡的非最优性,设计了一个罗宾汉机制,利用转移支付的思想来进一步提高训练模型的性能,并给出了罗宾汉机制的可持续的和收敛性证明。最后,在模拟数据集和真实数据集上和现有协作模式的充分对比,验证了所提出的组协作模式的高性能表现。
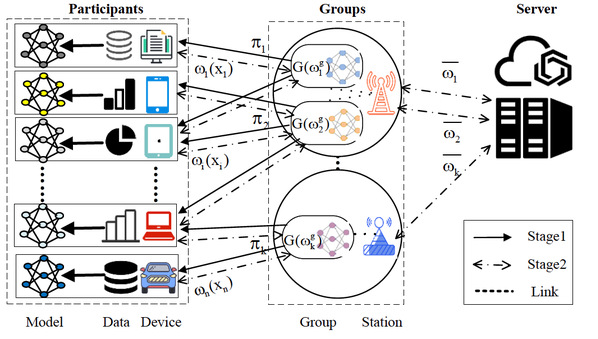
图2. 个性化联邦的组协同流程
论文3: Towards Fairness-Aware Time-Sensitive Asynchronous Federated Learning for Critical Energy Infrastructure (IEEE Transactions on Industrial Informatics)
关键能源基础设施(CEI)系统对国民经济和社会发展至关重要,但是当CEI与分布式机器学习技术相结合时容易受到网络攻击和数据隐私泄露等技术挑战。尽管联邦学习已成为一种新颖的符合隐私保护需求的分布式机器学习范式,但当复杂的联邦任务应用于CEI时,组织边缘计算节点之间的协作训练是是一件非常困难的调度任务,特别是在未来信息不可预知的异步联邦场景中,CEI系统必须立即做出不可撤销的决定关于是否雇用动态到达和离开的边缘计算节点。针对以上技术挑战,本文设计了兼顾公平意识和时间敏感的任务分配的异步联邦机制。首先,设计具有可靠性保障的多维契约机制,激励参与者诚实公正,实现时间固定场景下的性能最优化。其次,设计了一个多尺度的参与者招募机制来最小化任务时间开销,并给出了该问题的NP完全性证明,提出了一种基于松弛迭代优化的e-近似算法实现对时间成本的有效控制。大量真实数据和模拟数据的实验论证进一步了表明了本文所提出的机制在分布式任务调度中在协同性能、公平性以及时间开销上具有高性能表现。

图3. 异步联邦学习的任务处理流程
论文4:A Green Stackelberg-Game Incentive Mechanism for Multi-Service Exchange in Mobile Crowdsensing (ACM Transactions on Internet Technology)
尽管移动群智感知已经成为一种收集、分析和利用大量感知数据的绿色范式,但现有的激励机制并不能有效地激发用户在多服务交换应用中的积极参与和高质贡献,这是由于受制于其独有特征:海量异构用户具有不对称的服务诉求、工作者可以自由选择感知任务以及参与水平、并且异构型感知任务的不同价值属于敏感信息可能不会被相应的请求者诚实声明。为了解决以上问题,本文研发了一种绿色的Stackelberg博弈激励机制,以在降低感知平台负担的同时实现选择性公平、真实性、以及有界效率保障。首先,将多服务交换问题建模为一个由多领导者多追随者组成的Stackelberg多服务交换博弈模型,其中作为领导者的请求者首先选择奖励申报策略,从而为每个感知任务支付相应费用。然后,作为追随者的工作人员选择感知计划策略,以最大化个体效用。接下来,我们引入虚拟货币的概念,以保持用户之间的选择性公平性,并平衡服务请求和服务愿景,其中用户赚取/消费虚拟货币以提供/接受服务,再次,我们提出了两种新算法分别用于计算感知计划决定博弈和奖励声明决定博弈的唯一纳什均衡,这两种算法的输出共同组成了所提出博弈的唯一Stackelberg均衡。特别的,我们从理论上证明了所提出的机制具有三条理想性质。最后,与基线和理论优化方法相比,我们提供了广泛的评估结果,以支持所设计机制的正确性和有效性。
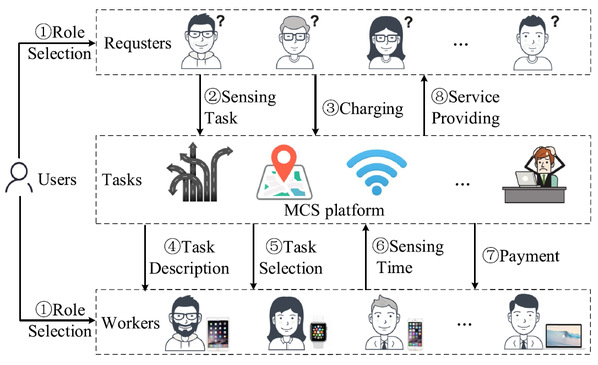
图4. 绿色Stackelberg激励机制在多服务交换移动群智感知系统中的交互流程
论文5: Extortion and Cooperation in Rating Protocol Design for Competitive Crowdsourcing (IEEE Transactions on Computational Social Systems)
众包作为一种利用人类智慧和活动来解决广泛任务的典范,通过向在线群体下的众多用户征求贡献来获得所需的数据或服务,提供了一种分布式、具有成本效益的方法。然而在监督不完善的情况下,众包中具有竞争利益的异质工人倾向于击败对手以获得更大的自我利益,自由和频繁的更换对手的竞争特点使得实际博弈场景更为复杂。为了将以上特征纳入讨论范畴,旨在加强合作同时剥削自私工作者,目的在于最大化请求者的效用,本文提出了一中增强合作与惩罚自私行为的激励机制设计问题,将二元评级与差异定价相结合,开发了一种新的评级协议,在满足可持续社会规范的充要条件下,设计了选择最优设计参数的低复杂度算法,大量的评估结果证明了我们所设计的评级协议的性能,并揭示了内置参数对设计参数的影响。以上工作为解决竞争性众包下迫使自利的劳动者服从社会规范,克服社会不良均衡的低效问题,提供了理论与技术支撑。
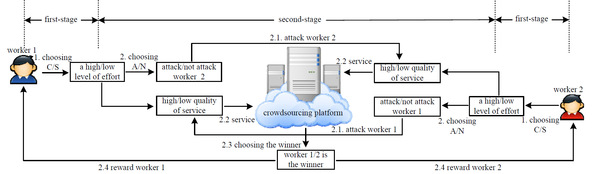
图5. 一种典型的众包竞争困境博弈
论文6:Truthful Incentive Mechanism Design via Internalizing Externalities and LP Relaxation for Vertical Federated Learning (IEEE Transactions on Computational Social Systems)
纵向联邦学习是一种多方联合建模应用的分布式机器学习新范式。高效激励有自我意识的客户端积极可靠地参与纵向联邦学习的协作可以提高模型训练的能耗效率。我们为纵向联邦学习开发了第一个真实的激励机制,它可以处理信息自我披露和社会效用最大化问题。通过内部化外部性设计转移支付规则,我们将客户端的效用与社会效用关联,使真实报告私人信息成为每个客户的主导策略。我们证明了该机制可以实现真实性和社会效用最大化,并通过线性松弛进一步优化了样本量决策规则,以满足不同场景的需求。合成数据集和真实数据集上的实验验证了该机制的性能优于当前的流行方法。纵向联邦学习的激励机制可以促进不同类型机构之间的机器学习合作,更加有效地利用本地数据和计算资源。
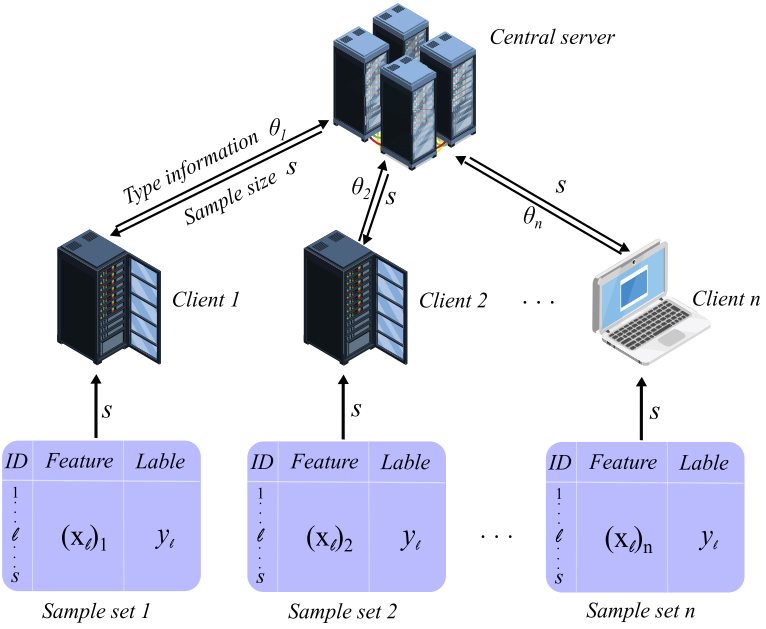
图6. 纵向联邦学习激励机制框架图
鲁剑锋教授自2022年1月正式入职pg电子官方网站,是湖北省“楚天学者”特聘教授、浙江省杰出青年基金获得者、中国计算机学会物联网/普适计算专委会执行委员、国家重点研发计划“物联网与智慧城市”重点专项答辩评审专家、湖北省/浙江省/广东省科技计划项目评审专家等。主要研究兴趣包括联邦学习、群智感知、博弈论及其应用等。近年来以第一作者/通讯作者在IEEE TIFS、IEEE JSAC、ACM TOIT、IEEE TII、IEEE TVT、IEEE TCSS、IEEE IOTJ、电子学报等国际著名学术期刊及会议上发表论文40余篇。先后主持国家自然科学基金3项、省部级课题5项。指导研究生获省/校优秀毕业生称号、优秀硕士学位论文、研究生国家奖学金、校长特别奖多人次,多人毕业后赴上海交通大学等著名高校读博深造。